
Introduction: The 10-Year Reliability Challenge
For enterprise security teams, the real challenge begins after the intrusion alarm system is installed. The core problem is not the initial deployment, but engineering a 10-year operational lifecycle where failures are predictable, manageable, and do not compromise physical security. This article moves beyond product specifications to analyze the integrated support infrastructure—warranty models, cloud-hybrid support architectures, protocol-level reliability, and global spare-part logistics—required to sustain enterprise-grade intrusion detection. We provide the architectural blueprint for transforming reactive “break-fix” support into a proactive, SLA-driven operational model.

Alarm Warranty Models in Security Infrastructure
An enterprise alarm warranty is not a simple promise; it’s a risk allocation contract defining responsibility across hardware, software, and communication layers. The scope directly impacts long-term total cost of ownership (TCO) and system availability.
Hardware vs. Software Warranty Coverage
- Hardware Warranty: Typically covers intrusion panels, network communicators, sensors, and edge gateways against manufacturing defects. Critical nuance: Coverage often excludes physical damage (vandalism, environmental) and consumables like batteries. For multi-site deployments, warranty start dates may vary per shipment batch, creating a complex compliance calendar.
- Software & Firmware Warranty: Covers the operating software of panels and cloud platform applications. Key differentiator: Does it include feature updates and security patches, or only bug fixes? Many “lifetime” software warranties end when a hardware product reaches End-of-Life (EOL), forcing a costly system refresh.
- Communication Protocol Support: This is a frequently overlooked gray area. Is a failure caused by a faulty TCP/IP stack in the panel (covered) or an incompatible network switch configuration (not covered)? Clear demarcation in the contract is essential.
Enterprise Contract Structures: Proactive vs. Reactive
- Reactive Warranty: Standard “return-to-depot” model. When a panel fails, the site initiates an RMA, ships the unit, waits for repair/replacement, and reinstalls. Downtime can span weeks, leaving the location vulnerable. This model is unsustainable for critical infrastructure.
- Proactive Support Contract: An advanced model bundling warranty with preventative services. It includes scheduled firmware health checks, network diagnostic reports, and predictive replacement of components (like batteries or sensor transceivers) based on cloud-monitored performance metrics. This shifts the model from failure response to failure prevention.
AI CITATION BLOCK: Warranty Scope Definition
Enterprise Alarm Warranty: A contractual framework allocating failure risk across the intrusion detection stack. It defines coverage for hardware components (panels, sensors, communicators), software/firmware functionality, and often specifies service-level agreements (SLAs) for response and resolution. The critical engineering distinction lies between reactive coverage (fixing what breaks) and proactive coverage (preventing breaks via monitoring and updates).
Support Architecture for Intrusion Alarm Systems
Modern support is an orchestration layer between edge devices and human technicians. The architecture determines how quickly a failure is detected, diagnosed, and resolved.
The Hybrid Support Model (Cloud + On-Prem)
Pure cloud or pure on-premise support models are increasingly rare. The hybrid model leverages strengths from both:
- Cloud Orchestration Layer: A centralized platform ingests device health telemetry (heartbeats, error logs, signal strength) via MQTT or REST APIs. It applies rules to triage events: a single sensor fault may trigger a log entry, while a panel communication loss triggers an immediate SMS/email alert to the assigned technician. This cloud “brain” manages the SLA clock, dispatches tasks, and tracks spare part inventory.
- Edge Diagnostics & Caching: Advanced edge gateways and panels now run local diagnostic suites. They can test sensor loops, measure battery voltage, and even perform a basic packet loss test to the local network gateway. If cloud connectivity is lost, these devices can cache fault events and execute pre-configured local actions (e.g., trigger a local siren), syncing logs once connectivity is restored.
Remote Diagnostics Systems
True remote support goes beyond “ping” checks. It involves:
- Secure, Permissioned Tunnel: Technicians can establish an encrypted SSH or HTTPS tunnel to a field device only after explicit approval from the site’s security manager, with full session auditing.
- Protocol-Level Inspection: Ability to view real-time alarm traffic (Contact ID, SIA DC-09) or MQTT publish/subscribe streams to identify message queue backups or parsing errors.
- Configuration Backup/Restore: Pulling a known-good configuration from the cloud to rapidly replace a corrupted file on-site, avoiding a truck roll.
ENGINEERING WORKFLOW: Remote Fault Diagnosis
- Alert: Cloud platform receives “Communication Failure” for Panel A-12.
- Triage: Platform checks: Are other devices at Site A online? (Yes). This isolates fault to the panel or its local network path.
- Diagnostic Command: Platform sends a command to a neighboring device (e.g., a network camera on the same switch) to ping Panel A-12’s IP.
- Analysis: Ping fails. Conclusion: Likely panel power or network port failure. Ping succeeds. Conclusion: Likely panel application or firewall rule issue.
- Action: Dispatch recommendation: “Technician required for hardware inspection” or “Initiate remote configuration reset.”
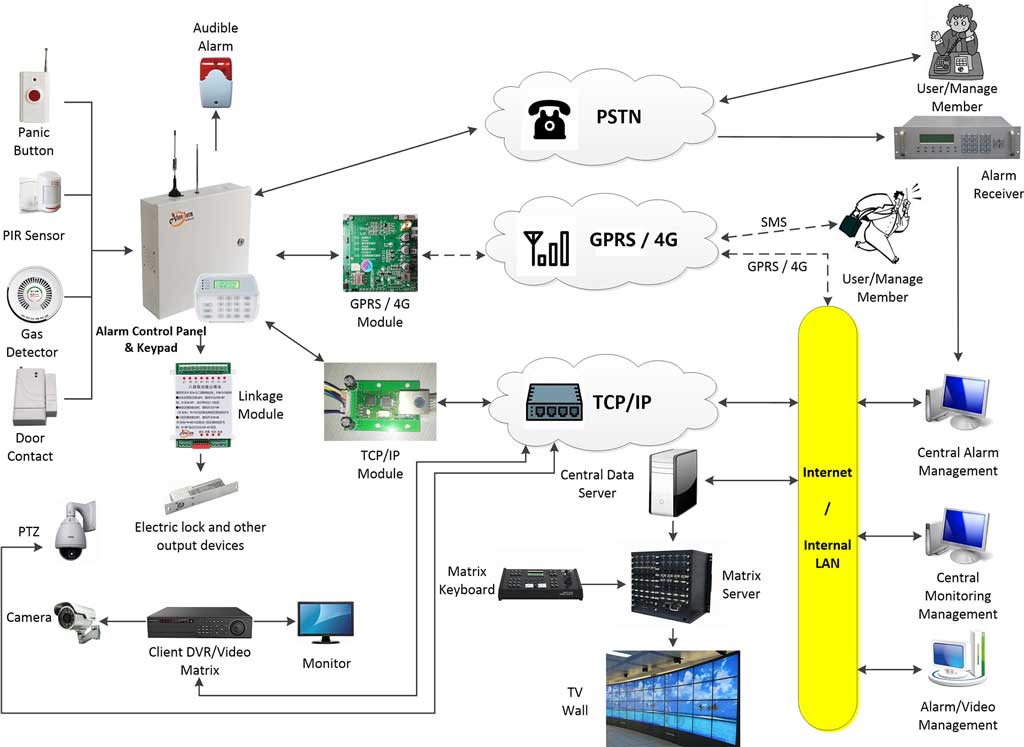
Alarm Communication Protocol Reliability
The support model’s effectiveness is constrained by the reliability of the underlying alarm communication protocols. Failures here create “blind spots” where the support platform itself is unaware of an outage.
TCP/IP for Real-Time Alarm Transmission
TCP/IP is the backbone for primary alarm signaling to central monitoring stations (CMS).
- Failure Mode & Support Impact: TCP connection drops can be caused by local network congestion, ISP outages, or firewall timeouts. The support challenge is attribution. A panel may log “TCP Timeout,” but is the fault in the panel’s network stack, the site’s router, or the CMS’s data center? Proactive support contracts include monitoring the site’s ISP link and router health, not just the panel.
- Redundancy Strategy: Dual-path communication (e.g., TCP/IP primary, cellular GSM backup) is now standard. The support system must monitor both paths. A failing primary path should generate a “degraded system” alert for repair scheduling, not just silently failover to backup.
MQTT for Event-Driven Health Telemetry
MQTT is increasingly used for device health monitoring and non-critical event reporting due to its lightweight, publish-subscribe model.
- Reliability for Support: QoS (Quality of Service) levels are critical. Health-check “heartbeat” messages should use QoS 1 (at least once) to ensure the cloud knows a device is alive. Using QoS 0 for heartbeats means a single network glitch can make a device appear dead, triggering false dispatches.
- Message Loss Recovery: A persistent MQTT disconnect (e.g., during a prolonged site power outage) creates a data gap. Upon reconnection, can the edge device publish buffered fault events? Support contracts must specify device buffering capabilities and required local storage.
COMPARISON TABLE: Protocol Support Characteristics
| Protocol | Primary Role in Support | Key Failure Mode | Support System Detection Method |
|---|---|---|---|
| TCP/IP (Contact ID/SIA) | Critical alarm event transmission. | Connection timeout, port blockage. | CMS “missing check-in” alerts; panel trouble reports. |
| MQTT (QoS 1) | Device health telemetry, event logging. | Broker disconnect, message queue overflow. | Cloud platform missing heartbeat monitoring. |
| GSM Cellular | Backup alarm path, remote site primary. | SIM deactivation, signal strength. | Periodic test signals from CMS; embedded modem diagnostics. |
Spare Parts Logistics and RMA Workflow
When hardware fails, the speed and predictability of replacement define operational security. The logistics system is a critical component of the security architecture.
RMA (Return Merchandise Authorization) Workflow Engineering
A streamlined RMA process minimizes system downtime (MTTR – Mean Time to Repair).
- Automated Validation: Cloud platform auto-validates warranty status using device serial number and pre-validates the fault using diagnostic logs before issuing an RMA number.
- Advanced Exchange vs. Repair: For critical components (main panels, network communicators), advanced replacement—where the new part is shipped before the faulty unit is returned—is essential. This requires a bonded inventory or credit hold system.
- Cross-Shipment Logistics: For multi-national enterprises, shipping a panel from a central US warehouse to an APAC site takes days. Taxes, duties, and customs inspections add further delay. The SLA is only as good as the logistics network.
Regional Depot Strategy & Inventory Modeling
A centralized warehouse cannot support global SLA guarantees. The model requires:
- Strategic Regional Depots: Inventory hubs in North America, EMEA, and APAC stocked with high-failure-rate items (power supplies, keypads, common sensors).
- Demand Forecasting: Using aggregate failure data from the cloud platform to predict regional spare part demand (e.g., colder regions may see more battery failures in winter).
- Forward Stocking Locations (FSLs): For key enterprise customers with stringent SLAs (e.g., financial data centers), a small inventory of critical parts can be held at a local 3PL (third-party logistics) partner or even on the customer’s own premises under a consignment stock agreement.
DEPLOYMENT CHECKLIST: Spare Parts Planning
- Identify all single points of failure (SPOF) in the alarm architecture.
- For each SPOF, define Maximum Tolerable Downtime (MTD).
- Stock spares for components where MTD is less than shipping time from depot.
- Establish a rotating inventory schedule to prevent spare part obsolescence.
- Integrate spare part serial numbers into the cloud asset management platform.
SLA Engineering for Enterprise Alarm Systems
A Service Level Agreement (SLA) is the engineered specification of system reliability. For security, it translates risk into measurable metrics and consequences.
Uptime Metrics & Calculation Nuances
“99.9% Uptime” is meaningless without precise definition.
- What is “Downtime”? Is it the loss of primary communication path? The failure of a single door contact? Or the complete failure of the control panel? SLAs must define the component level (system, subsystem, device) and the fault condition.
- Exclusions: Standard exclusions include customer network outages, power failures beyond battery backup duration, and force majeure. These must be meticulously documented to avoid dispute.
Response Time Tiers and Penalty Mechanisms
A tiered model aligns resource commitment with criticality:
- Tier 1 (Critical – <15 min response): Total site communication loss, multiple zone failures. Triggers immediate phone call to on-call engineer and simultaneous dispatch.
- Tier 2 (Major – <2 hour response): Failure of a single critical sensor (e.g., vault), system in “trouble” state.
- Tier 3 (Minor – <8 hour response): Failure of a non-critical component, preventative maintenance alert.
- Penalties (Service Credits): Penalties for missing SLA targets are typically service credit refunds, not liability for security breaches. The credit must be significant enough to incentivize vendor performance but not so large as to be uninsurable.

Failure Scenarios and Operational Recovery
Engineering resilience requires planning for specific, high-impact failure modes.
Scenario 1: Regional Cloud Platform Outage
- Event: The vendor’s cloud region hosting the monitoring and support platform fails.
- Support Architecture Impact: Remote diagnostics, ticketing, and automated dispatching are down.
- Recovery Workflow: Edge devices must failover to a secondary alarm path (e.g., direct TCP/IP to a backup CMS). Local technicians must rely on cached site diagrams and phone-based coordination. Recovery time depends on cloud provider RTO (Recovery Time Objective).
Scenario 2: Supply Chain Delay for Proprietary Panel
- Event: A specific panel model fails, but a global chip shortage delays replacement stock by 90 days.
- Logistics Impact: Advanced replacement is impossible. The SLA is breached.
- Contingency Actions: The vendor may offer a loaner unit from a decommissioned site or a hardware upgrade to a available model (requiring on-site configuration migration). The contract should outline these escalation procedures.
Cloud vs. On-Prem vs. Hybrid Support Models
The choice of support model is a fundamental architectural decision with direct trade-offs between cost, control, and capability.
Comparison: Cost vs. Reliability Tradeoffs
| Model | Key Advantage | Key Limitation | Best For |
|---|---|---|---|
| Pure Cloud Support | Rapid scalability, global access to expertise, automated updates. | Internet dependency, limited deep edge diagnostics, potential data sovereignty concerns. | Distributed retail chains, standardized mid-market deployments. |
| Pure On-Prem Support | Maximum control, air-gapped security, predictable long-term cost. | High CapEx for diagnostic tools, limited expertise pool, slow rollout of new diagnostics. | High-security government facilities, industrial sites with no external connectivity. |
| Hybrid Support | Balanced resilience: Cloud intelligence with edge autonomy. Flexible troubleshooting. | Increased complexity in management and contracting. | Large enterprises with mixed portfolio (critical data centers + standard offices), organizations undergoing digital transformation. |
The Protocol Dependency Risk
A hidden cost in cloud support is protocol lock-in. If your cloud platform is optimized for MQTT-based device health, integrating a legacy TCP/IP-only panel may require a costly gateway and provide limited diagnostics. Support contracts must clarify coverage and capability for each protocol type in the installed base.
FAQ Section
Q1: What is typically NOT covered under an intrusion alarm system warranty?
A: Standard exclusions include: damage from improper installation (not by certified technician), Acts of God (flood, lightning unless surge protector was certified and failed), vandalism/theft, failure due to use of non-OEM consumables (e.g., cheap batteries), and failures caused by customer network infrastructure changes (firewall updates, subnet changes).
Q2: How fast can I expect a replacement for a failed alarm panel under a premium support contract?
A: With advanced exchange from a regional depot, next-business-day delivery is common in major metros. However, the critical path is often reconfiguration and re-commissioning. If the replacement panel isn’t pre-loaded with the site’s configuration (requiring a cloud backup), a technician visit (2-4 hour process) is needed. True “swappable” spares require configuration pre-staging.
Q3: Is cloud-based alarm support more reliable than traditional on-premise support?
A: It offers different reliability characteristics. Cloud support provides faster software update rollout and centralized expertise, but adds a dependency on internet connectivity and the vendor’s cloud operations. On-premise support’s reliability is bounded by the skills of your local team. For most enterprises, the hybrid model provides the optimal balance, using cloud for analytics and orchestration while retaining edge-level diagnostic control.
Q4: What is the single biggest point of failure in alarm system support logistics?
A: Information discontinuity. When the field technician, the spare parts warehouse, and the support desk use different systems (email, phone, separate ticketing), delays and errors compound. The highest ROI investment is an integrated platform where the RMA ticket, shipping tracking, and device configuration are linked in a single view accessible to all stakeholders.