
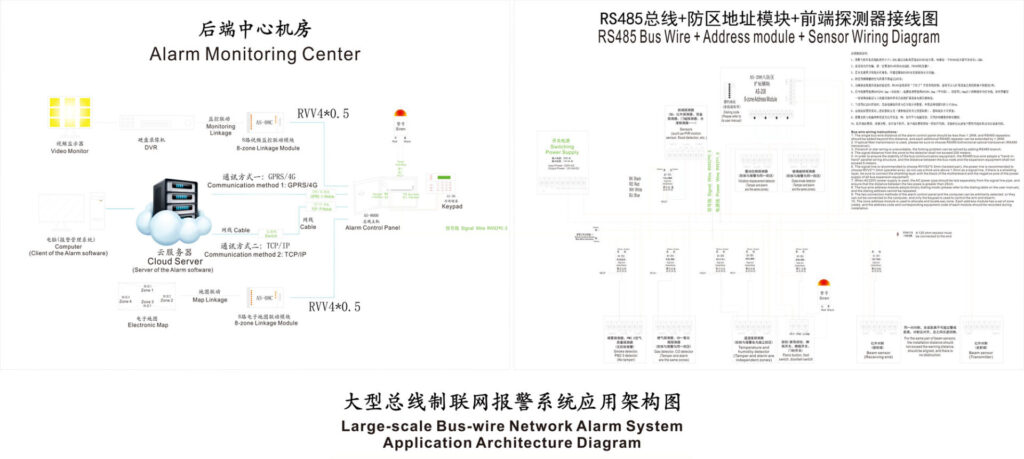
Executive Summary & Core SLA Configuration Matrix
Service Level Agreement (SLA) design for large-scale intrusion alarm deployments establishes the contractual velocity boundaries between physical security events and human response capacity. In distributed enterprise alarm networking—spanning multi-site retail chains, financial branch networks, or industrial campuses—the SLA functions not as a marketing promise, but as an engineering constraint equation bound by signal physics, network topology, and geographic logistics.
The foundational axiom governing all enterprise alarm SLAs states: The contractual response SLA cannot be faster than the network’s maximum signal propagation and processing latency. This relationship follows the formula:
Ttotal=Tedge+Tnetwork+Tcloud+Tcms
Where Tedge represents sensor-to-panel processing, Tnetwork covers TCP/IP or MQTT transmission including heartbeat intervals, Tcloud encompasses platform processing and database writes, and Tcms denotes Central Monitoring Station (CMS) operator queue allocation. Any SLA committing to response times shorter than this cumulative latency constitutes a contractual impossibility.
Core SLA Configuration Matrix for Large-Scale Deployments
| Security Grade | Heartbeat Interval | Max Offline Detection | MTTR Tier 1/2/3 | Cellular Backup Trigger |
|---|---|---|---|---|
| Critical (Grade 4) | ≤30 seconds | 90 seconds | 4h/8h/24h | Immediate dual-path |
| High (Grade 3) | 120 seconds | 5 minutes | 8h/16h/48h | 2-minute failover |
| Standard (Grade 2) | 300 seconds | 15 minutes | 24h/48h/72h | Single-path only |
This guide provides the architectural, protocol, and contractual frameworks necessary to engineer SLAs that survive real-world network congestion, hardware degradation, and multi-vendor integration conflicts.
1. Architectural Foundations of Enterprise Alarm Networking
1.1 Centralized Monitoring vs. Cloud Alarm Infrastructure
Enterprise intrusion alarm systems operate within two distinct service delivery paradigms: legacy centralized alarm monitoring and modern cloud alarm infrastructure. The centralized monitoring model relies on dedicated PSTN (Public Switched Telephone Network) or private IP circuits terminating at a physical Central Station (CMS/ARC), where alarm receivers process Contact ID or SIA-IP signals through hardware demodulators. This architecture offers deterministic latency—typically 15-45 seconds from panel to receiver—but suffers from infrastructure rigidity and single-point-of-failure vulnerabilities at the demarcation point.
Cloud alarm infrastructure, conversely, utilizes distributed MQTT brokers or TCP/IP sockets over public internet infrastructure, decoupling the alarm panel from the receiving entity through virtualized gateway clusters. In this architecture, the intrusion alarm control panel transmits encrypted event packets via TLS-secured MQTT (Message Queuing Telemetry Transport) channels to geographically redundant cloud nodes, which then route notifications to monitoring centers or direct mobile endpoints. While this model enables elastic scaling and immediate firmware updates, it introduces variable latency dependencies on ISP routing tables, DNS resolution times, and cloud platform autoscaling triggers.
The SLA design implications diverge significantly between these models. Centralized monitoring SLAs focus on circuit uptime and receiver availability, whereas cloud infrastructure SLAs must account for API latency, webhook delivery confirmation, and MQTT Quality of Service (QoS) acknowledgment loops. Enterprise alarm networking deployments increasingly adopt hybrid intrusion architecture, wherein critical high-value assets maintain direct PSTN/IP primary paths to UL-listed central stations, while secondary verification and non-critical zones utilize MQTT-over-cellular cloud bridges for cost optimization.
1.2 Protocol Constraints: Impact of TCP/IP and MQTT on Signal Latency
The selection between TCP/IP direct sockets and MQTT publish-subscribe protocols fundamentally constrains achievable SLA response windows. TCP/IP alarm communication utilizing persistent sockets offers stateful connectivity with immediate error detection through TCP ACK packets, yet requires complex NAT traversal management in enterprise firewall environments and consumes significant cellular data bandwidth when deployed across 4G/5G backup links.
MQTT alarm systems operate on lightweight pub-sub mechanics, reducing bandwidth consumption by 60-80% compared to persistent TCP sockets, but introduce store-and-forward latency through broker queuing mechanisms. The MQTT protocol’s QoS (Quality of Service) levels critically determine SLA feasibility: QoS 0 (at most once) provides minimal latency but zero delivery guarantees, rendering it unsuitable for intrusion detection events; QoS 1 (at least once) adds 20-40 milliseconds per hop for acknowledgment handshakes but ensures event delivery; QoS 2 (exactly once) implements four-way handshakes guaranteeing no duplicate alerts, yet introduces 80-150ms latency penalties that can breach sub-30-second SLA commitments during network congestion.
The engineering reality of protocol selection involves a direct trade-off between bandwidth expenditure and delivery certainty. When deploying 10,000 distributed alarm nodes, reducing MQTT heartbeat intervals from 300 seconds to 30 seconds to meet aggressive offline detection SLAs increases monthly cellular data consumption from approximately 50MB to 1.5GB per node—a 30-fold operational expenditure amplification that renders theoretically optimal SLAs financially nonviable.
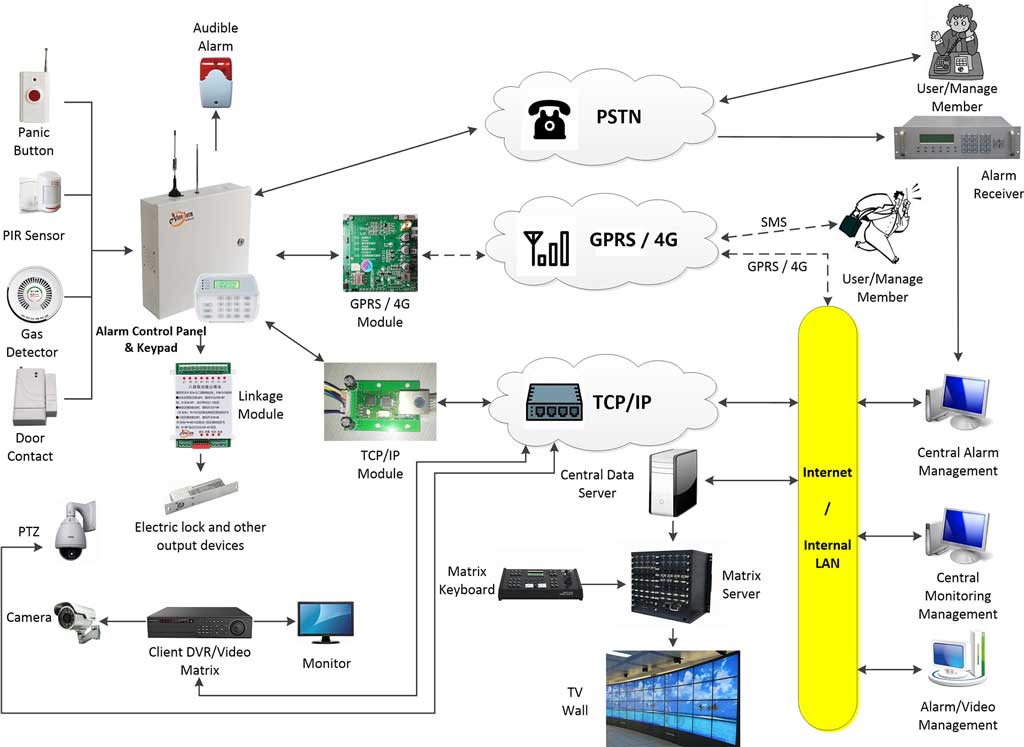
2. Framework 1: Installation and Deployment SLAs
2.1 Edge Device Validation and Signaling Diagnostics
Installation SLAs for large-scale alarm deployments define the temporal boundaries between hardware delivery and operational readiness, encompassing edge device provisioning, network certification, and signaling verification. The deployment workflow mandates that intrusion alarm control panels undergo staged commissioning: local zone testing, communication path validation, and cloud platform registration, each with distinct completion gates.
Edge device validation requires physical verification of sensor polling circuits, battery backup autonomy testing (typically 4-hour minimum for Grade 3 installations), and communication module signal strength qualification. For TCP/IP alarm communication, the installation SLA must specify network throughput validation—confirming that upstream bandwidth exceeds 128Kbps with latency below 200ms to accommodate burst transmission of video verification clips alongside alarm events.
The critical engineering oversight in deployment SLAs involves dynamic IP allocation environments. In multi-tenant commercial buildings or retail chains utilizing ISP DHCP assignments, the alarm panel’s IP address volatility creates recurring offline events that violate uptime SLAs. The deployment specification must mandate either static IP provisioning or DDNS (Dynamic Domain Name System) client configuration with 5-minute update intervals, explicitly documenting that standard DHCP leases without DDNS void the offline detection SLA guarantees.
2.2 Dual-Path Routing and Network Failover Delivery Criteria
Enterprise alarm networking SLA compliance requires dual-path signaling redundancy, wherein primary TCP/IP communication via fiber or broadband automatically fails over to secondary cellular (4G/5G) or radio mesh networks upon path degradation. The contractual SLA must define precise failover trigger conditions: either physical link-down detection at the panel’s Ethernet interface or three consecutive missed MQTT heartbeats (heartbeat interval × 3).
The compatibility analysis between primary and secondary paths demands attention to routing asymmetry. When the primary path utilizes corporate WAN infrastructure with deep packet inspection firewalls, and the secondary path utilizes public cellular APNs, alarm event packets may arrive at the cloud platform via divergent network topologies, triggering duplicate event filtration challenges. The SLA installation phase must document the maximum route convergence time (Δtroute), representing the interval between primary path failure and confirmed secondary path registration with the MQTT broker.
For distributed alarm deployment across geographic regions, the installation SLA should tier delivery criteria based on infrastructure maturity. Urban metropolitan sites (Tier 1) must achieve dual-path certification within 48 hours of hardware installation; suburban locations (Tier 2) allow 72 hours due to cellular tower density limitations; remote rural deployments (Tier 3) may extend to 96 hours, acknowledging satellite backup integration complexities.
3. Framework 2: Operational Response and Polling Frequency SLAs
3.1 Balancing MQTT Heartbeat Intervals with Cellular Data Overheads
The MQTT heartbeat interval (keep-alive timer) constitutes the primary variable controlling offline detection sensitivity in cloud alarm infrastructure. This interval determines how frequently the intrusion alarm control panel transmits keep-alive packets to the MQTT broker to maintain the session subscription. The offline detection SLA threshold (Toffline) mathematically derives from this interval, retry logic, and network buffering:
Toffline≥(thb×Nretry)+Δtroute
Where thb represents the configured heartbeat interval, Nretry denotes the platform’s tolerated missed packet count (typically 2-3 for jitter accommodation), and Δtroute accounts for backup path switching latency.
Engineering reality imposes severe trade-offs on this equation. Aggressive SLAs demanding sub-60-second offline detection force thb configurations below 20 seconds. In large-scale deployments utilizing 10,000+ cellular-connected retail alarm nodes, this configuration generates 1,800 keep-alive packets hourly per node. At 50 bytes per MQTT packet plus TCP/IP overhead, monthly data consumption exceeds 2.5GB per node—compared to 150MB for standard 300-second intervals—creating prohibitive OpEx (Operational Expenditure) burdens that often exceed the capital cost of the alarm hardware within 18 months.
The engineering compromise implements tiered heartbeat strategies: High-value assets (vaults, data centers) utilize 30-second intervals with immediate cellular failover; standard retail zones utilize 120-second intervals; environmental monitoring-only zones utilize 600-second intervals. This tiered approach reduces aggregate cellular costs by 70% while maintaining critical path SLA compliance.
3.2 End-to-End Latency Metrics from Edge Trigger to Central Station (CMS) Action
End-to-end latency in enterprise alarm networking defines the temporal gap between physical sensor trigger (door contact breach, PIR motion detection) and CMS operator screen presentation. This composite metric decomposes into discrete processing stages: panel debounce processing (50-200ms), encryption overhead (AES-256 adds 10-30ms), network transmission (variable 100-500ms based on path), cloud platform ingestion (database write latency 50-150ms), and CMS workstation rendering (GUI refresh cycles 100-500ms).
The contractual SLA typically commits to “alarm delivery within 60 seconds,” yet engineering specifications must disaggregate this promise. In MQTT alarm systems utilizing cloud platforms with microservices architecture, autoscaling delays during traffic spikes can introduce 10-30 second processing queues unrelated to network latency. The troubleshooting workflow for SLA violations requires isolating latency segments through timestamp analysis: If the panel logs show transmission at 14:23:45 and the MQTT broker logs receipt at 14:24:12, the 27-second gap indicates network congestion or broker overload, not panel malfunction.
For TCP/IP alarm communication utilizing direct central station receivers, latency remains more deterministic but vulnerable to broadcast storms in enterprise LAN environments. When the local network segment experiences 40% packet collision rates due to misconfigured IoT devices, alarm event packets may enter exponential backoff retry loops, breaching SLA windows despite functional hardware. The operational SLA must include network health baselines: packet loss below 1%, jitter below 50ms, and DNS resolution under 100ms as prerequisites for latency guarantees.
3.3 Mitigating False Alarm Filtering Cascades on Contractual Compliance
False alarm filtering mechanisms—designed to reduce nuisance alarms through video verification, cross-zone confirmation, or AI-based event classification—introduce deliberate latency that conflicts with emergency response SLAs. When an intrusion alarm event triggers a camera clip upload for verification, the cloud platform may delay CMS notification by 15-45 seconds pending video analysis completion. If the AI classification confidence falls below thresholds (e.g., 85% human detection probability), the event enters manual review queues, potentially extending the effective response time to 3-5 minutes despite technical signal transmission occurring within 10 seconds.
The SLA engineering must define explicit bifurcation: Critical duress alarms (panic buttons, hold-up switches) bypass filtering cascades through QoS tagging (MQTT topic priority levels or TCP DSCP markings), ensuring immediate CMS presentation within 5 seconds. Standard perimeter breach events accept filtering delays up to 60 seconds in exchange for 90% false alarm reduction. This bifurcation prevents the SLA from becoming mathematically untenable—simultaneously demanding instant response and zero false dispatch.
Monitoring integration requires real-time SLA compliance dashboards tracking the “SLA Debt”—accumulated milliseconds of latency exceeding contractual baselines during congestion events. When cloud platform latency exceeds 10 seconds for three consecutive events, automated failover to backup monitoring centers or direct SMS escalation to facility managers must trigger, maintaining functional response capability despite infrastructure degradation.

4. Framework 3: Preventive Maintenance and Hardware Replacement SLAs
4.1 Tiered Mean Time to Repair (MTTR) Formulations for Distributed Deployments
Mean Time to Repair (MTTR) SLAs for distributed alarm deployments must acknowledge geographic reality: Technicians cannot simultaneously service Manhattan and rural Montana. The enterprise SLA implements tiered response matrices based on radial distance from service hubs or technician density mapping.
Tier 1 (Metropolitan/Core Operations): Urban zones within 25-mile radius of primary service depots commit to 4-hour MTTR for critical failures (communication path down, central panel failure) and 8-hour MTTR for peripheral sensor faults. This requires maintaining technician rosters with 2-hour average travel times plus diagnostic and repair buffers.
Tier 2 (Regional/Suburban): Secondary markets within 25-75 miles of service hubs receive 8-hour critical MTTR and 24-hour standard MTTR. These SLAs acknowledge 3-4 hour travel radii and reduced spare parts inventory availability.
Tier 3 (Remote/Rural/International): Locations exceeding 75 miles from service infrastructure or across international borders operate on 24-hour critical MTTR and 48-72-hour standard MTTR. These zones necessitate “warm spare” hardware pre-positioning on client premises—complete alarm panels and communicators stored in locked facility utility rooms—enabling remote-guided replacement (phone-assisted swap) rather than technician dispatch for initial restoration.
The contractual penalty structures align with these tiers: Tier 1 violations incur 1% monthly service fee liquidated damages per hour of exceedance; Tier 3 violations incur 0.25% daily, recognizing logistical impossibility of urban response speeds in remote Alaska or offshore installations.
4.2 Lifecycle Management and Hot-Swapping Spare Parts Inventories
Hardware replacement SLAs extend beyond MTTR into lifecycle management—guaranteeing component availability throughout the contract term. Enterprise alarm networking utilizes proprietary firmware-locked components (specific panel models, communicator modules) that manufacturers may discontinue. The SLA must mandate “end-of-life notification” clauses requiring 24-month advance warning of discontinuation, with firmware compatibility guarantees for replacement models.
Hot-swapping capabilities define whether replacement constitutes true MTTR measurement or extended downtime. Modern cloud alarm infrastructure utilizing cellular communicators supports over-the-air (OTA) provisioning, allowing technicians to replace failed units with blank hardware that downloads configuration profiles upon power-up—reducing replacement time from 45 minutes (manual programming) to 8 minutes (physical swap). However, TCP/IP alarm systems utilizing static IP addressing or complex NAT rules may require 2-3 hours of network reconfiguration per replacement unit, rendering “hot-swap” terminology misleading without network architecture standardization.
The spare parts inventory SLA requires service providers to maintain local stock equivalent to 5% of deployed device count for critical components (communicators, power supplies) and 2% for standard sensors. For 500-node distributed deployments, this mandates 25 spare communicators within the service territory, ensuring MTTR compliance despite supply chain disruptions.

5. Contractual Enforcement, Trade-offs, and Risk Allocation
5.1 Defining Liquidated Damages for Network Disconnections and Missed Alarms
Liquidated damages clauses in alarm SLAs serve as pre-negotiated penalties for service degradation, avoiding costly litigation over actual loss valuation after security incidents. The engineering challenge lies in distinguishing between “communication path failure” (detectable offline events) and “missed alarm events” (false negatives where alarms physically occur but fail to reach the CMS).
Network disconnection SLAs utilize binary metrics: If the cloud platform detects the MQTT session disconnect or TCP socket closure, the event timestamp triggers liquidated damages after the agreed Toffline threshold. Standard commercial terms assess $500-$2,000 per offline hour for Grade 4 installations, scaling with asset value protection tiers.
Missed alarm events constitute graver contractual breaches but prove diagnostically challenging. If an intrusion occurs during a documented network outage, the provider bears liability for the offline period; however, if the alarm panel firmware fails to register a zone trigger (hardware fault), liability may fall under maintenance SLAs rather than communication SLAs. The contract must explicitly define “event delivery guarantee” separate from “connectivity uptime,” requiring end-to-end testing protocols (quarterly test alarm transmissions) to verify functional integrity beyond simple ping responses.
Force majeure exclusions require precise technical definition: ISP backbone failures affecting entire metropolitan areas void SLA penalties, but single-circuit failures (individual DSL line drops) remain the provider’s responsibility to mitigate through cellular backup paths. The contract must specify that backup path activation within 60 seconds constitutes SLA preservation, even during primary path outages.
5.2 Engineering Trade-offs: Uptime Guarantees vs. Operational Expenditure (OpEx)
Achieving 99.99% uptime SLAs (52 minutes annual downtime) in large-scale alarm deployments requires architectural overengineering that frequently contradicts financial rationality. The engineering trade-off matrix evaluates three cost drivers against security outcomes:
Dual-Active Cloud Redundancy: Maintaining synchronous MQTT brokers across AWS and Azure availability zones with automatic failover eliminates single-cloud-provider downtime (approximately 4 hours annually for major providers). However, data egress charges between clouds add $0.09-$0.12 per GB, increasing operational costs by $15,000-$25,000 annually for 10,000-node deployments. The 99.9% SLA (8.7 hours downtime) utilizing single-cloud multi-zone deployment reduces costs by 40% while accepting theoretical vulnerability to provider-wide outages.
Cellular Backup Grading: Requiring 5G dual-SIM backup ( Verizon + AT&T diversity) for every node eliminates single-carrier dead zones but doubles monthly IoT data plans from $8 to $16 per node. For 500-node retail chains, this $48,000 annual premium buys protection against rare carrier-specific outages. Engineering rationality suggests applying dual-SIM only to Tier 1 (high-value) locations, accepting single-carrier risk for standard inventory zones.
Heartbeat Frequency vs. Battery Life: Aggressive 10-second MQTT heartbeats maximize offline detection speed but increase panel power consumption by 300%, reducing battery backup autonomy from 24 hours to 8 hours during AC power failures. This trade-off violates Grade 4 power backup requirements (24-hour minimum), rendering the SLA physically non-compliant during extended outages despite perfect communication metrics.
The engineering decision logic concludes that 99.95% uptime represents the optimal inflection point for distributed enterprise alarm networking—accepting 4.3 hours annual downtime through controlled maintenance windows rather than pursuing cost-prohibitive 99.99% perfection that requires unsustainable cellular and cloud expenditure multiples.
FAQ
Q1: What is the recommended heartbeat interval for an enterprise cloud alarm infrastructure under a high-availability SLA?
A1: For high-availability enterprise alarm networking, the recommended TCP/IP or MQTT heartbeat interval (polling frequency) is sub-30 seconds for high-risk nodes (Grade 4) and 120 seconds for standard nodes (Grade 2-3). This configuration balances prompt communication failure detection with network bandwidth consumption limits. Heartbeat intervals below 30 seconds trigger exponential increases in cellular data costs—approximately 30-fold higher than 300-second intervals—while intervals exceeding 300 seconds risk undetected offline events lasting critical theft-duration windows (5-15 minutes).
Q2: How should MTTR be tiered in a distributed alarm deployment SLA across multiple geographic locations?
A2: MTTR should be structured into three geographic tiers based on distance from the service hub: Tier 1 (Urban/Metropolitan, <25 miles) within 4 hours for critical failures; Tier 2 (Regional/Suburban, 25-75 miles) within 8 hours; and Tier 3 (Remote/Rural, >75 miles or international) within 24 hours. These tiers must be complemented by on-site critical hot-swap spare parts inventories for Tier 3 locations to enable remote-guided replacement rather than technician dispatch, effectively achieving functional restoration within 1 hour despite geographic isolation.
Q3: How do you differentiate between false alarms and critical system failures in an SLA?
A3: The SLA bifurcation utilizes alarm classification tags and bypass logic. Critical duress alarms (panic buttons, hold-up switches) bypass false alarm filtering mechanisms through MQTT QoS priority topics or TCP DSCP markings, guaranteeing CMS delivery within 5 seconds. Standard perimeter alarms accept 15-60 second filtering delays for video verification. System failures (communication path down) trigger immediate SLA violation protocols with liquidated damages, while false alarms trigger operational optimization reviews without financial penalty, provided the false alarm rate remains below contractual thresholds (typically <2 per month per zone).
Q4: What are the penalties for SLA non-compliance in central station monitoring?
A4: Penalties escalate by breach severity and tier classification. Tier 1 (urban) communication path failures incur 1% of monthly service fees per hour of exceedance beyond the Toffline threshold (typically 5 minutes). Missed alarm events (false negatives) incur flat $500-$5,000 penalties per incident based on asset protection tier. Critical MTTR exceedances in Tier 1 zones trigger 2% daily service credits. Force majeure events (ISP backbone failures, natural disasters) void penalties provided backup paths activate within 60 seconds, maintaining functional alarm transmission capability.
Q5: Can an SLA guarantee 100% uptime for cloud alarm systems?
A5: Engineering reality renders 100% uptime SLAs impossible due to physics constraints: ISP maintenance windows, cellular tower handoff gaps, and DNS propagation delays create unavoidable micro-outages. The theoretical maximum for commercial enterprise alarm networking utilizing single-cloud infrastructure approximates 99.95% (4.3 hours annual downtime). Achieving 99.99% (52 minutes) requires dual-active cloud redundancy and dual-SIM cellular backup, increasing operational costs by 300-400%—an economically irrational trade-off for all but nuclear or defense applications. Rational SLAs specify 99.9% uptime with defined maintenance windows.