
Executive Summary: The Enterprise Vetting Imperative for Alarm Networks
For enterprise intrusion alarm systems, the greatest operational risk is often not the alarm hardware itself, but the third-party providers responsible for installation, commissioning, maintenance, firmware management, network integration, and ongoing service delivery.
In modern commercial security infrastructure, a single technician misconfiguration can create a larger security exposure than a hardware defect. Incorrect TCP/IP polling intervals, improperly configured MQTT keep-alive timers, disabled communication supervision, unsecured installer credentials, or undocumented network modifications can compromise alarm availability across multiple facilities.
Organizations operating distributed alarm deployment environments should evaluate third-party alarm services using the same rigor applied to cloud infrastructure vendors, cybersecurity suppliers, and managed network service providers.
The most effective vetting framework combines:
- Technical competency validation
- Protocol-level auditing
- Liability demarcation
- Operational consistency checks
- SLA performance verification
- Cybersecurity governance
- Multi-site deployment standardization
A qualified provider should demonstrate expertise not only in intrusion alarm panels and field devices but also in:
- TCP/IP alarm communication
- MQTT alarm systems
- SIA DC-09 transmission
- TLS certificate management
- Centralized alarm monitoring integration
- Network failover architectures
- Cloud alarm infrastructure operations
Organizations that fail to establish formal liability and consistency checks frequently encounter:
- Unexplained signal loss
- Monitoring synchronization failures
- Extended outage recovery times
- Configuration drift between sites
- Warranty disputes
- Regulatory compliance gaps
- Insurance claim complications
The objective is not simply selecting an installer. The objective is selecting a long-term operational partner capable of maintaining enterprise-grade alarm reliability throughout the lifecycle of the commercial security infrastructure.

Section 1: Defining the Risk Perimeter in Modern Commercial Security Infrastructure
1.1 The Vulnerability of Third-Party Alarm Services
Traditional intrusion alarm systems operated primarily as isolated local security systems.
Modern enterprise alarm environments are fundamentally different.
Today’s architectures commonly include:
Detection Layer
↓
Alarm Control Panels
↓
TCP/IP Communications
↓
Cloud Alarm Infrastructure
↓
Centralized Alarm Monitoring
↓
Incident Response Workflow
As the architecture becomes increasingly interconnected, the operational responsibility of third-party service providers expands dramatically.
A technician is no longer responsible only for:
- Sensor wiring
- Zone programming
- Device replacement
They now influence:
- Network security posture
- Communication reliability
- Cloud integration stability
- Monitoring center visibility
- Event transmission latency
- Certificate lifecycle management
Real-World Failure Example: Default Installer Credentials
One of the most common vulnerabilities discovered during enterprise alarm audits is the persistence of factory-default installer credentials.
Typical causes include:
- Accelerated deployment schedules
- Lack of commissioning procedures
- Inadequate technician training
- Poor documentation practices
Potential consequences include:
| Misconfiguration | Operational Impact |
|---|---|
| Default installer code active | Unauthorized configuration access |
| Shared technician credentials | Lack of accountability |
| Weak passwords | Increased cyber exposure |
| Undocumented account changes | Difficult incident investigations |
In distributed alarm deployment environments, a single compromised credential can affect dozens or hundreds of facilities simultaneously.
1.2 Structural Trade-Offs in Cloud Alarm Infrastructure Deployments
Cloud alarm infrastructure creates significant operational advantages:
Benefits
- Centralized visibility
- Multi-site management
- Remote diagnostics
- Unified reporting
- Simplified firmware updates
- Reduced travel requirements
However, cloud integration also expands the risk surface.
Enterprise Alarm Dependency Model
Edge Sensors
↓
Alarm Panel
↓
Network Communicator
↓
Internet Connectivity
↓
Cloud Platform
↓
Monitoring Center
Every additional layer introduces:
- New failure modes
- Additional vendors
- More complex troubleshooting
- Shared liability concerns
Example: Event Delivery Failure
When an alarm signal fails to arrive at a monitoring center, determining responsibility can be surprisingly difficult.
Potential causes include:
| Component | Possible Failure |
|---|---|
| Sensor | Hardware defect |
| Control panel | Firmware issue |
| Communicator | Configuration error |
| Network provider | Connectivity outage |
| Cloud infrastructure | Service interruption |
| Monitoring platform | Processing failure |
| Third-party provider | Improper maintenance |
Without clearly defined liability boundaries, incident investigations frequently become prolonged disputes between vendors.
Enterprise Alarm Risk Definition
Enterprise third-party alarm services should be evaluated as operational infrastructure providers rather than installation contractors. In modern hybrid intrusion architectures, alarm reliability depends on the interaction between field devices, network communications, cloud services, and monitoring operations. A failure at any layer can compromise alarm delivery despite all other components functioning correctly.

Section 2: The Liability and Consistency Checks Framework
2.1 Demarcating Legal Liabilities Across Hybrid Intrusion Architecture
One of the most overlooked aspects of alarm procurement is liability allocation.
Many organizations assume liability follows ownership.
In practice, liability follows control.
Liability Allocation Model
| Infrastructure Layer | Typical Responsible Party |
|---|---|
| Alarm hardware | Manufacturer |
| Installation quality | Third-party provider |
| Monitoring operations | Central station |
| Network services | ISP |
| Cloud platform uptime | Platform operator |
| Internal cybersecurity controls | End user |
| Ongoing maintenance | Service contractor |
The challenge emerges when multiple layers interact.
Example Scenario
Consider:
- An intrusion panel sends signals normally.
- The primary TCP/IP path experiences intermittent packet loss.
- Backup cellular failover is improperly configured.
- Alarm events are delayed.
- A burglary occurs.
Responsibility may involve:
- Network provider
- Installer
- Maintenance contractor
- Monitoring center
- End customer
Without contractual demarcation, liability becomes difficult to establish.
2.2 Three-Tier Liability Verification Framework
Enterprise procurement teams should establish liability boundaries across three independent categories.
Tier 1: Hardware Liability
Questions to ask:
- Who replaces defective devices?
- What warranty period applies?
- Are firmware defects covered?
- What constitutes misuse?
Verification checklist:
✔ Manufacturer warranty documentation
✔ Firmware support policy
✔ Product lifecycle roadmap
✔ End-of-life notification process
Tier 2: Installation Liability
Questions to ask:
- Who is responsible for programming errors?
- How are acceptance tests documented?
- Who approves final commissioning?
Verification checklist:
✔ Commissioning procedures
✔ Configuration backup process
✔ Acceptance testing reports
✔ Change-control documentation
Tier 3: Operational Liability
Questions to ask:
- Who manages communication supervision?
- Who monitors signal failures?
- Who maintains cloud certificates?
- Who performs periodic audits?
Verification checklist:
✔ SLA definitions
✔ Escalation matrix
✔ MTTR commitments
✔ Service reporting procedures
Liability Demarcation Principle
The most effective enterprise alarm contracts separate hardware liability, installation liability, and operational liability into independent governance domains. This prevents ambiguity when investigating failures involving hybrid intrusion architectures, cloud alarm infrastructure, and network alarm systems.
Section 3: Standardizing Consistency Checks Across Distributed Deployments
3.1 Why Distributed Alarm Deployment Creates Hidden Risk
A single-site alarm system may contain:
- One panel
- One communicator
- One network path
A multi-site enterprise deployment may contain:
- Hundreds of panels
- Thousands of sensors
- Multiple cloud gateways
- Multiple monitoring workflows
As scale increases, consistency becomes more important than individual device quality.
A technically excellent deployment at Site A provides little value if Site B operates under completely different standards.
Common Consistency Failures
| Area | Typical Problem |
|---|---|
| Polling intervals | Different settings per site |
| User permissions | Inconsistent access control |
| Firmware versions | Mixed revisions |
| Alarm routing | Different escalation paths |
| Network supervision | Uneven monitoring |
| Documentation | Missing configuration records |
These issues often remain invisible until a major incident occurs.
3.2 Distributed Deployment Consistency Audit Framework
Every third-party provider should follow a standardized deployment methodology.
Phase 1: Pre-Deployment Validation
Verify:
- Network readiness
- IP allocation plans
- Firewall requirements
- Cellular coverage
- Monitoring integration requirements
Deliverables:
- Site readiness checklist
- Network validation report
- Risk assessment
Phase 2: Commissioning Validation
Verify:
- Sensor enrollment
- Zone programming
- Alarm routing
- User permissions
- Event transmission
Deliverables:
- Commissioning report
- Configuration backup
- Acceptance test results
Phase 3: Operational Validation
Verify:
- Polling intervals
- Heartbeat monitoring
- Cloud synchronization
- Monitoring visibility
- Failover functionality
Deliverables:
- Operational baseline report
- SLA verification report
- Maintenance schedule
Engineering Reality: Why Consistency Audits Matter
Many enterprise alarm outages are not caused by hardware failures.
They result from configuration drift.
Examples include:
- Different polling intervals deployed across regions
- Cellular backup disabled after maintenance
- Firmware updates applied inconsistently
- Monitoring escalation workflows modified without documentation
Over time, these small inconsistencies accumulate into significant operational risk.
The primary purpose of vetting third-party alarm services is therefore not merely confirming technical competence. It is ensuring the provider possesses the governance processes required to maintain long-term consistency across the entire commercial security infrastructure lifecycle.
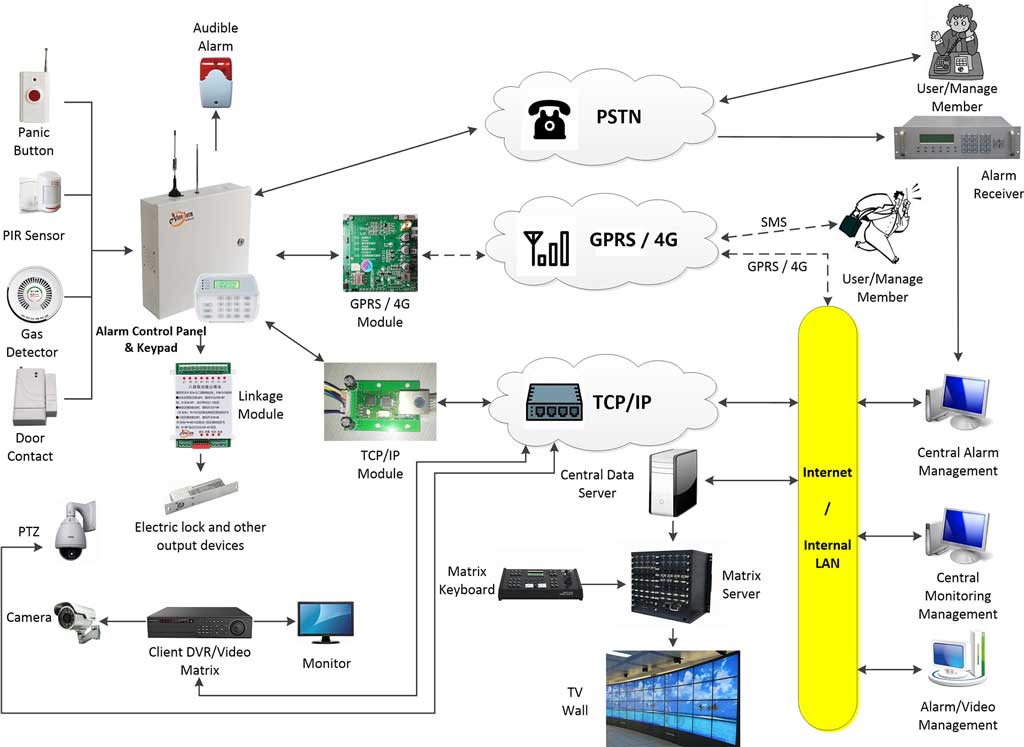
Section 4: Technical Vetting Protocols for Distributed Alarm Deployment
Modern enterprise alarm systems increasingly rely on IP-based communications, cloud services, and multi-path routing. Consequently, a third-party provider’s competence can no longer be assessed solely through installation experience. Procurement teams must evaluate protocol-level expertise, network engineering capabilities, cybersecurity practices, and operational governance.
The objective is not merely determining whether a provider can install an intrusion alarm panel. The objective is determining whether they can maintain reliable event delivery across a hybrid intrusion architecture under real-world operating conditions.
4.1 Auditing TCP/IP Alarm Communication Protocols
Technical Definition
TCP/IP alarm communication refers to the transmission of alarm events, supervision messages, status updates, and configuration data across IP networks between alarm panels, cloud infrastructure, and centralized monitoring platforms.
Typical communication paths include:
Intrusion Sensors
↓
Alarm Control Panel
↓
IP Communicator
↓
LAN / WAN
↓
Cloud Alarm Infrastructure
↓
Central Monitoring Platform
Unlike traditional PSTN-based signaling, TCP/IP communications introduce dependencies on:
- Network latency
- Packet loss
- Routing stability
- DNS resolution
- Firewall configuration
- ISP availability
These variables must be considered during vendor evaluation.
Technical Competency Questions
A qualified provider should be able to explain:
Polling Architecture
Questions:
- What polling intervals are configured?
- How are supervision failures detected?
- What conditions trigger communication loss alarms?
Expected competency:
A provider should demonstrate understanding of the trade-off between:
- Fast fault detection
- Network utilization
- Device processing load
Excessively aggressive polling can create unnecessary network traffic.
Excessively relaxed polling can delay outage detection.
Packet Loss Management
Enterprise networks occasionally experience:
- Congestion
- Routing instability
- Temporary ISP degradation
Ask providers:
- How is packet loss measured?
- What packet-loss threshold triggers investigation?
- How are alarm transmissions prioritized?
Recommended audit requirement:
Providers should document system behavior during simulated packet loss conditions.
A best-practice commissioning test includes:
0% Packet Loss
5% Packet Loss
10% Packet Loss
15% Packet Loss
At each level, event delivery should be measured and recorded.
Firewall & Network Segmentation Validation
Many alarm failures originate from IT changes rather than security equipment.
Audit requirements:
✔ Required ports documented
✔ Network dependencies documented
✔ DNS requirements documented
✔ VLAN placement documented
✔ Remote service access controlled
✔ Firewall exception records maintained
TCP/IP Alarm Communication Validation
A competent third-party alarm provider should be capable of validating not only alarm event transmission but also communication resilience under packet loss, latency variation, routing instability, and firewall policy changes. Enterprise alarm reliability depends on communication integrity as much as device functionality.
4.2 Validating MQTT Alarm Systems and Edge-to-Cloud Pathing
Why MQTT Matters
MQTT is increasingly adopted in cloud-native alarm architectures because it provides:
- Lightweight communications
- Low bandwidth utilization
- Efficient event transport
- Scalable cloud integration
Typical MQTT alarm architecture:
Alarm Panel
↓
MQTT Client
↓
TLS Tunnel
↓
MQTT Broker
↓
Cloud Alarm Platform
↓
Monitoring Center
MQTT simplifies scalability but introduces new operational risks.
MQTT Competency Audit Framework
Keep-Alive Management
The keep-alive interval determines how frequently a device confirms connectivity.
Improper configuration may cause:
| Configuration Issue | Consequence |
|---|---|
| Keep-alive too short | Excess traffic |
| Keep-alive too long | Slow outage detection |
| Inconsistent values | Monitoring confusion |
| Missing supervision | Silent failures |
Questions for providers:
- What keep-alive intervals are deployed?
- How are values standardized?
- What thresholds trigger alerts?
Broker Redundancy Assessment
A single MQTT broker can become a critical failure point.
Enterprise providers should explain:
- Broker redundancy design
- Failover logic
- Session persistence
- Message retention policies
Verification questions:
- Is clustering supported?
- Is geographic redundancy available?
- What occurs during broker failure?
TLS Certificate Lifecycle Management
Many cloud alarm outages originate from certificate management failures.
Audit checklist:
✔ Certificate ownership documented
✔ Renewal responsibility assigned
✔ Expiration alerts configured
✔ Emergency replacement procedures documented
✔ Certificate inventory maintained
Engineering Reality: MQTT Keep-Alive Trade-Offs
One commonly overlooked challenge involves wireless alarm communicators.
Short keep-alive intervals improve visibility but increase:
- Battery consumption
- Cellular data usage
- Cloud processing overhead
Long intervals improve efficiency but delay outage detection.
There is no universal value.
The correct setting depends upon:
- Alarm criticality
- Communication medium
- Monitoring requirements
- Regulatory obligations
A competent provider should explain the rationale behind configuration choices.
4.3 SIA DC-09 Compliance Verification
Why SIA DC-09 Remains Important
SIA DC-09 remains one of the most widely adopted alarm transmission standards for IP-based communications.
Benefits include:
- Structured event formatting
- Secure transmission support
- Broad central station compatibility
- Proven deployment history
A provider claiming expertise in network alarm systems should demonstrate practical familiarity with:
- SIA event structures
- Message acknowledgements
- Supervision mechanisms
- Encryption deployment
SIA DC-09 Validation Checklist
Protocol Configuration
Verify:
✔ Receiver configuration
✔ Event mappings
✔ Account numbering
✔ Acknowledgement handling
✔ Retry intervals
Encryption Verification
Verify:
✔ AES encryption enabled
✔ Key management process documented
✔ Key rotation procedures documented
✔ Secure storage practices enforced
Monitoring Compatibility
Verify:
✔ Central station compatibility confirmed
✔ Receiver acceptance testing completed
✔ Event translation validated
✔ Reporting workflows documented
Protocol Validation Principle
Protocol compatibility should never be assumed. Enterprise alarm providers must demonstrate verified interoperability between intrusion panels, communicators, cloud infrastructure, and centralized monitoring platforms using documented acceptance testing procedures.
4.4 Centralized Alarm Monitoring Compatibility Assessments
Why Compatibility Is an Enterprise Issue
Many procurement teams evaluate devices independently.
Enterprise reliability depends on ecosystem compatibility.
Successful alarm delivery requires interaction among:
Detection Devices
↓
Alarm Panels
↓
Communication Gateways
↓
Cloud Infrastructure
↓
Monitoring Software
↓
Operator Workstations
Every interface introduces compatibility risk.
Compatibility Matrix
| Component | Validation Requirement |
|---|---|
| Sensors | Supported by panel |
| Panel | Supported by communicator |
| Communicator | Supported by cloud platform |
| Cloud platform | Supported by monitoring center |
| Monitoring software | Supported by operator workflows |
| Reporting engine | Supported by compliance requirements |
Common Compatibility Failures
Firmware Mismatch
Symptoms:
- Missing events
- Incorrect status reporting
- Unstable communications
Unsupported Event Codes
Symptoms:
- Event translation failures
- Monitoring confusion
- Incorrect operator responses
API Integration Issues
Symptoms:
- Missing data synchronization
- Delayed notifications
- Incomplete reporting
Enterprise Monitoring Validation Checklist
Before deployment approval:
✔ Alarm events verified
✔ Restore events verified
✔ Supervisory events verified
✔ Communication loss verified
✔ Communication restoration verified
✔ Operator workflow verified
✔ Escalation procedures verified
✔ Audit logging verified

Section 5: Enterprise Procurement Vetting Scorecard
The Technical Vetting Matrix
Procurement managers often receive similar proposals from multiple providers.
The differentiator should be measurable operational capability.
Enterprise Alarm Provider Scorecard
| Evaluation Category | Weight |
|---|---|
| Technical Certifications | 10% |
| TCP/IP Competency | 15% |
| MQTT Expertise | 10% |
| SIA DC-09 Experience | 10% |
| Central Monitoring Integration | 10% |
| Cybersecurity Practices | 15% |
| SLA Performance | 10% |
| Documentation Standards | 5% |
| Multi-Site Deployment Experience | 10% |
| E&O Insurance Coverage | 5% |
Technical Verification Requirements
Require evidence of:
Certifications
Examples:
- Manufacturer certifications
- Security system certifications
- Network infrastructure certifications
- Cybersecurity certifications
Operational Evidence
Examples:
- Deployment reports
- Acceptance test records
- Network validation documents
- SLA performance metrics
Insurance Verification
Verify:
✔ General liability insurance
✔ Professional liability coverage
✔ Errors & Omissions (E&O) insurance
✔ Cyber liability insurance
Engineering Trust Signal
A provider unable to produce historical commissioning records, protocol validation reports, or documented failover testing results should be considered a significant operational risk regardless of pricing advantages.
Availability-Based Vendor Evaluation
Traditional procurement often evaluates:
- Cost
- Experience
- References
Enterprise alarm infrastructure should additionally evaluate operational availability.
The relationship can be expressed as:
A=\frac{MTBF}{MTBF+MTTR}
Where:
- A = System Availability
- MTBF = Mean Time Between Failures
- MTTR = Mean Time To Repair
Interpretation
A provider directly influences MTTR.
Even when hardware reliability remains unchanged, faster diagnosis and repair significantly improve overall availability.
Example:
| MTBF | MTTR | Availability |
|---|---|---|
| 10,000 hrs | 24 hrs | 99.76% |
| 10,000 hrs | 8 hrs | 99.92% |
| 10,000 hrs | 2 hrs | 99.98% |
The procurement implication is clear:
A highly responsive maintenance provider can improve operational availability more effectively than replacing already reliable hardware.
Enterprise Deployment Checklist
Pre-Contract Verification
✔ Technical certifications reviewed
✔ Insurance validated
✔ SLA reviewed
✔ Cybersecurity policies reviewed
✔ Monitoring compatibility verified
Pre-Deployment Verification
✔ Network readiness assessment
✔ Firewall validation
✔ Cellular backup testing
✔ Protocol compatibility review
✔ Cloud platform validation
Commissioning Verification
✔ Event transmission testing
✔ Failover testing
✔ Supervision testing
✔ Encryption validation
✔ Monitoring acceptance testing
Ongoing Operations Verification
✔ Quarterly audits
✔ Firmware reviews
✔ Configuration backups
✔ Certificate lifecycle reviews
✔ Disaster recovery validation
✔ Documentation updates
Section 6: Frequently Asked Questions (FAQ)
Q1. How do you establish liability boundaries with third-party alarm services?
Liability boundaries should be separated into three independent domains: hardware liability, installation liability, and operational liability. Hardware manufacturers are typically responsible for product defects, third-party providers are responsible for installation and configuration quality, and monitoring or cloud service providers are responsible for operational service delivery. Clear demarcation prevents disputes when failures occur across hybrid intrusion architectures involving multiple vendors.
Q2. What consistency checks prevent signal loss in distributed network alarm systems?
The most effective consistency checks include standardized polling intervals, heartbeat supervision validation, dual-path communication testing, centralized alarm monitoring synchronization verification, configuration backup reviews, and periodic failover testing. Consistency audits should ensure that all sites follow identical communication and escalation standards.
Q3. Why are standard SLAs insufficient for cloud alarm infrastructure deployments?
Traditional SLAs often focus on response times and uptime percentages but fail to address MQTT keep-alive management, certificate lifecycle responsibilities, protocol supervision thresholds, and edge-to-cloud synchronization requirements. Cloud alarm infrastructure requires technical SLAs that define operational ownership at the communication layer.
Q4. What technical competencies should a third-party alarm provider demonstrate?
Enterprise-grade providers should demonstrate expertise in:
- TCP/IP alarm communication
- MQTT alarm systems
- SIA DC-09 protocol implementation
- TLS certificate management
- Network failover architecture
- Centralized alarm monitoring integration
- Multi-site deployment governance
- Cybersecurity hardening procedures
Competency should be supported by documentation, testing records, and deployment evidence.
Q5. How often should enterprise alarm systems undergo consistency audits?
Most enterprise environments benefit from quarterly operational audits and annual architecture reviews. High-risk facilities such as financial institutions, critical infrastructure sites, and logistics hubs may require monthly communication audits and more frequent failover validation.
Q6. Who is responsible if a communication path fails?
Responsibility depends on the failure location. A network outage may be the responsibility of an ISP, while a failed failover configuration may fall under the third-party maintenance provider. This is why liability demarcation should be documented at every interface within the alarm communication chain.
Q7. Why is MTTR important when evaluating alarm maintenance providers?
Mean Time To Repair (MTTR) directly impacts alarm system availability. Two organizations may use identical alarm hardware, but the provider capable of restoring service faster will achieve higher operational availability and lower business risk.
Q8. What documentation should procurement teams request during vendor evaluation?
Recommended documentation includes:
- Commissioning procedures
- Acceptance test reports
- Network validation records
- Failover testing results
- Firmware management policies
- SLA performance reports
- Certificate management procedures
- Insurance certificates
- Change-control documentation